Active Learning 이란?
이 글은 능동학습(Active Learning)에 대한 개념과 문제를 소개하고, 이를 해결하기 위한 몇 가지 방법을 소개합니다. 연구 분야에 대해서 소개할 기회들이 몇몇 있었는데 그때마다 만들었던 자료들을 모아서 작성하였습니다. (그래서 영어와 한글이 아직 혼용되어 있어요..)
What is Active Learning?
Active Learning (AL)은 레이블되지 않은 데이터셋으로부터 어떤 데이터를 레이블링(labeling)할 지 선택하는 방법입니다. 일반적으로 모델을 학습하기 위해선 label이 있는 데이터가 많이 필요한데, 이는 적고 label되지 않은 데이터는 많습니다. 이때, 모든 데이터를 레이블링하는 것은 비용이 많이 들기 때문에 어떤 데이터를 선별적으로 레이블링을 하여 모델의 성능을 효율적으로 높일 수 있을지를 고민합니다. 즉, Active learning은 labeling cost가 높을 때 어떤 데이터에 레이블링을 해야 우리 모델의 성능이 더 높아질 수 있을지 고려하여 일부 more informative data를 선별하는 작업입니다.
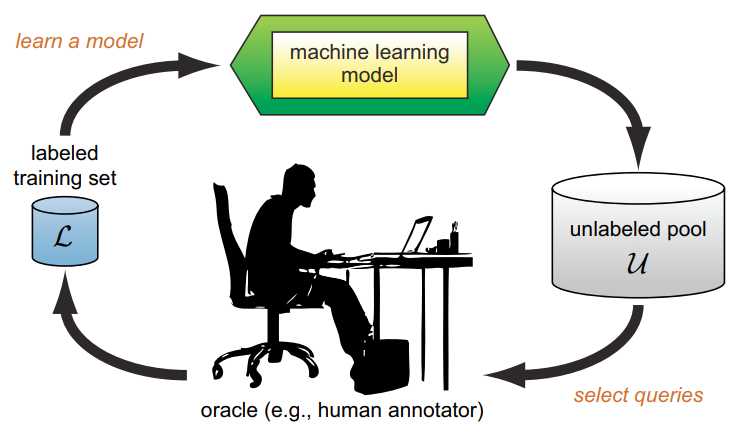
source: [Settles, 2009]
예를 들어, 의료계에서 환자의 폐 사진으로부터 암이 있는지 없는지 판별하는 문제를 풀고 있다고 해봅시다. 여기서 실제 암이 있다 없다라고 레이블링한 폐 CT 이미지는 굉장히 적고, 레이블 되지 않은 이미지는 비교적 많이 있습니다. 우리는 의사에게 이 이미지를 레이블링해달라고 부탁할 때 이 레이블링의 비용이 만만치 않음을 알고 있습니다. 이때, Active Learning을 이용해 충분히 모델의 성능을 높일 수 있는 informative한 이미지셋을 선택하여 의사에게 레이블링을 요청한다면 비용을 상당히 줄일 수 있습니다. 실제로, 랜덤으로 아무 이미지 100장을 의사에게 레이블링을 요청하는 것보다 Active Learning을 이용해 선별한 중요한 이미지를 요청하여 더 적은 데이터 수로도 더 높은 정확도에 도달함을 많은 AL 논문에서 보였습니다.
source: Pixabay
Problem Statement
Active Learning의 목표는 labeled set이 매우 적고 labeling을 할 수 있는 budget이 적을 때, 가장 높은 성능에 도달할 수 있는 informative한 unlabeled set의 subset을 찾는 active learning 알고리즘을 개발하는 것입니다.
Challenges
Exploration-exploitation tradeoff
‘informative’한 데이터를 어떻게 판별할까요? 우리는 이를 찾기 위해 RL 등에서 흔히 사용되는 exploration-exploitation 개념을 고려하였습니다. Exploration은 데이터가 어떻게 분포하고 있는지를 캡쳐하는 것이며, Exploitation은 현재 모델이 모르는 것을 캡쳐하려는 것입니다.
exploration-exploitation의 간단한 예로, 수학 문제집을 들 수 있습니다. 우리가 수학 문제를 풀 때, 대표적인 유형의 문제를 풀면서 전반적인 개념을 이해하는 데에 도움이 될 수 있습니다. 혹은 어려운 유형의 문제를 풀면서 내가 취약한 개념을 깊이 이해하는 데에 도움이 될 수 있습니다. 모두 수학에 대한 이해력을 높이기 위함입니다. 마찬가지로 exploration을 통해 전반적인 데이터 분포를 이해하고 exploitation을 통해 모델이 취약한 불확실한 부분을 명확히 이해하게 할 수 있습니다.

